
Google Cloud オペレーション スイートで特定処理の”エラー率”を検知してみた
-
2021年3月31日
はじめまして。ビリングチームのSです。
ビリングチームで管理しているシステムの、とある処理のエラー率を検知して閾値を超えたら通知してほしいという要望がありました。
障害検知の方法としては、一定期間内にエラーが発生した件数をカウントして閾値を超えたら通知するという方法が一般的かと思います。
しかし、今回のシステムの要件としては、時間帯によって呼ばれる処理回数の差を考慮し、たとえエラー件数が多かったとしても、それが全体の1%程度であれば通知する必要がないとしました。
そのためエラー件数ではなく、エラー率を検知して通知しようというのが今回の記事の主旨です。
構成
サーバはGCPで構築している為、Google Cloudのオペレーション スイート(旧称 stackdriver)を利用することにしました。
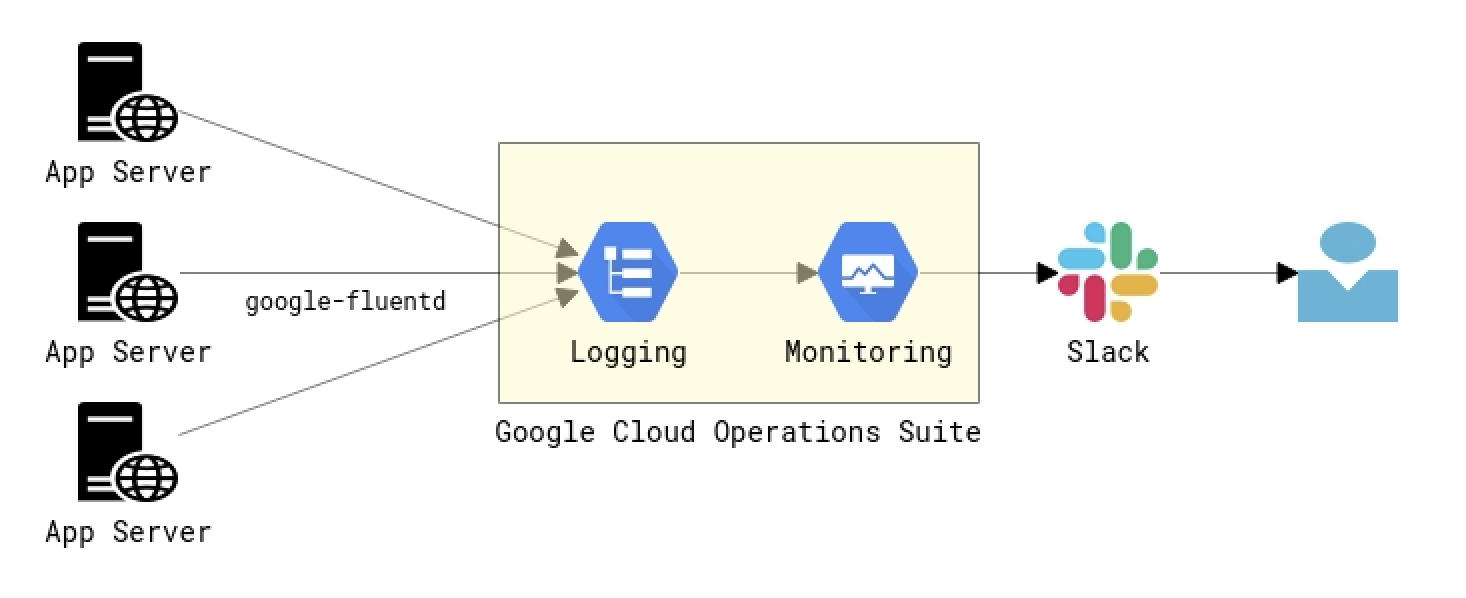
- ・google-fluentdで各サーバからログを収集
- ・Cloud Loggingでログベース指標の作成
- ・Cloud Monitoringで通知設定
- ・Slackで通知
google-fluentdの設定
Loggingエージェント google-fluentdを対象のサーバにinstallし実行する事でログをGCPに収集し指標とする事が可能になります。
構造化ロギングを有効にしてインストールを行います。
環境によって手順が異なりますので公式ドキュメントをご確認ください。
インストール
$ curl -sSO https://dl.google.com/cloudagents/add-logging-agent-repo.sh $ sudo bash add-logging-agent-repo.sh $ sudo yum install -y google-fluentd $ sudo yum install -y google-fluentd-catch-all-config-structured
エージェントのバージョン確認
$ rpm --query --queryformat '%{NAME} %{VERSION} %{RELEASE} %{ARCH}\n' google-fluentd
google-fluentd 1.8.3 1.el7 x86_64
$ rpm --query --queryformat '%{NAME} %{VERSION} %{RELEASE} %{ARCH}\n' google-fluentd-catch-all-config-structured
google-fluentd-catch-all-config-structured 1.0 1.el7.centos noarch
起動、ステータス確認
$ sudo service google-fluentd start Starting google-fluentd (via systemctl): [ OK ] $ sudo service google-fluentd status google-fluentd is running [ OK ]
構造化ロギングについて
Cloud Loggingの構造化ログとはjsonPayloadフィールドを使用してペイロードに構造を追加するログエントリのことです。
ログデータをjsonPayloadに格納する事で後述するログベースの指標作成時にクエリのキーとして利用可能になります。
jsonPayloadのフィールドには、Logging エージェントによって特別なものと認識され、LogEntryとして扱われるものがあります。
この記事では下記が該当します。
- ・severity :ログレベル。INFOやERRORなどが定義されている。
- ・time:ログ出力の時刻
構造化ロギングを利用するためにはLoggingエージェントの構成ファイル(/etc/google-fluentd/config.d)にパーサーを作成する必要があります。
以下はtomcatのパーサー作成例です。
ログレコード(入力)
2021-01-01 00:00:00.000 [http-nio-9090-exec-7] [INFO] [jp.cocone.sample.SampleClass:21] success code:0"
Tomcatパーサー
<source>
@type tail
format multiline
format_firstline /^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}/
format1 /^(?<time>[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}) (?<thread>\[.*\]) \[(?<severity>[A-Z]*)\] (?<message>.*)$/
time_format %Y-%m-%d %H:%M:%S.%L
path /[Tomcat_Installation_Directory]/logs/catalina.out.%Y-%m-%d.log
pos_file /var/lib/google-fluentd/pos/tomcat-multiline.pos
read_from_head true
tag sample-log
</source>
ログエントリ(出力)
{
"jsonPayload": {
"thread": "[http-nio-9090-exec-7]",
"message": "[jp.cocone.sample.SampleClass:21] success code:0""
},
"timestamp": "2020-12-31 15:00:00.000Z",
"severity": "INFO",
"logName": "projects/[PROJECT-ID]/logs/sample-log"
}
google-fluentdインストールにデフォルトで有効になっている標準パーサーも含まれます。
公式ドキュメントでご確認ください。
ログの追加
Cloud Loggingのログベースの指標にはログエントリをカウントする設定とログ中の数値を抽出して分布指標を使う設定があります。
今回はエラー率を取りたいので分布指標で使うための数値をログに仕込みます。
成功の場合は0、失敗の場合は100を設定することで期間内に抽出した数値の平均値をエラー率とします。
try {
//エラー率を取得したい処理
//処理成功時のログ
logger.info(“success code:0”)
} catch (MyException e) {
//処理失敗時のログ
logger.info(“error code:100”)
}
Cloud Loggingでログベースの指標の作成
前項で収集したログをフィルタリングし指標として登録します。
詳細な設定方法については公式ドキュメントをご確認ください。
Google Cloud Platformのロギング -> ログベースの指標 -> 指標を作成から設定を行います。

分布指標を使うので指標タイプはDistributionを選択します。

指標の名前、説明、仕込んだログを抽出するためのフィルタ、取りたい数値が含まれているフィールド名、数値抽出のための正規表現を入力します。
入力が完了したらログをプレビューから抽出内容の確認ができます。
Metrics Explorerで作成した指標の確認
Resource typeとMetricの組み合わせを一つの時系列としてグラフで表示する事ができます。
Google Cloud Platformのモニタリング -> Metrics Explorerで先ほど作成したログベースの指標を確認してみます。

Resource type:フィルタ作成時に指定したresource.typeを指定します。
Metric:作成した指標を指定します。今回の場合だとlogging/user/demo_error_rateになります。
Aggregator:集計方法。平均値を取りたいのでmeanを選択します。
Period:期間を設定します。今回は5分毎の平均を出します。

表示例です。
ログベースの指標作成後からログの収集が開始されます。それ以前に遡って確認することは出来ないので注意が必要です。
Cloud Monitoringで通知設定
Resource typeとMetricの組み合わせを一つの時系列として、設定した閾値を超えた場合に通知を飛ばします。
Google Cloud Platformのモニタリング -> アラート -> ADD POLICYから設定します。
今回はエラー率が30%を超えたら通知するように設定します。

TargetはMetrics Explorerで設定した内容と同じです。
Configurationが通知のトリガー設定箇所になります。
Condition triggers if:複数の時系列があった場合の通知トリガーの設定です。今回時系列は一つなのでAny time series violatesを選択します。
- ・Any time series violates:いずれかの時系列で閾値を超えたとき
- ・Percent of time series violates:複数の時系列があったときに閾値を超えた時系列が指定した割合を上回ったとき
- ・Number of time series violates:複数の時系列があったときに閾値を超えた時系列が指定した数を上回ったとき
- ・All time series violate:全ての時系列が閾値を超えたとき
Condition:Thresholdの値がどのように変化したら通知するかを設定します。30%を超えたら通知したいのでis aboveを選択します。
- ・is above:Thresholdの値以上になったとき
- ・is below:Thresholdの値以下になったとき
- ・increases by:前回からThresholdの値分増加したとき
- ・decreases by:前回からThresholdの値分減少したとき
- ・is absent:値が取得できなかったとき
Threshold:閾値を設定。30%で通知したいので30を入力
For:どれくらいの期間閾値を超えたら通知するかを設定します。
- ・most recent value:閾値を超えた瞬間
- ・{数値} minutes:{数値} 分の間閾値を超えたとき
次に通知チャネルを指定します。
通知チャネルの管理については公式ドキュメントをご確認ください。

Notify on incident resolutionにチェックを入れることで値が正常に戻ったときにも通知が来るように設定できます。
最後に通知内容を設定します。

アラート名と本文を記載してSAVEをクリックすれば登録完了です。

Slackに通知が飛ぶようになりました。
最後に
若干トリッキーなやり方になった気がしますがエラー率を検知して通知できるようになりました。
ビリングチームでは一緒にシステムを良くしてくれる仲間を大募集中です。
みなさまのエントリーをお待ちしています!




